There are some things compilers aren't always great at, notably vector (SIMD) code. This isn't so much that vector code is much more difficult to compile than scalar code (although it is a bit), but moreso that vector support on CPUs is a complete mess of different standards, so compiling code that will work well across a wide range of hardware is a pain. As an example, here's a diagram of the current state of vector extensions on x86:
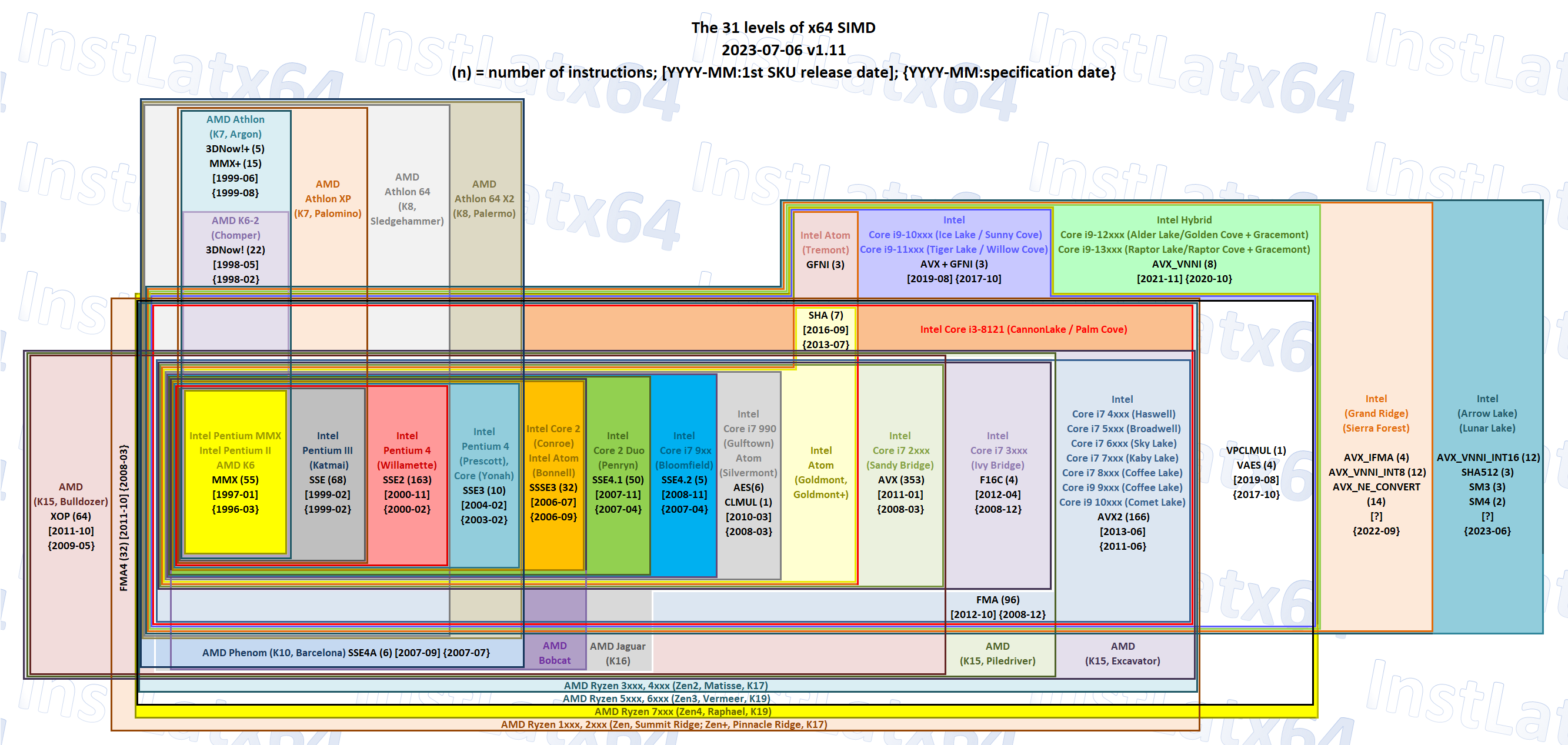
Vector heavy code will typically be implemented using intrinsics to target specific hardware capabilities. Intrinsics aren't exactly assembly language, but they map directly to assembly language for a given processor. For consoles this is relatively simple, as someone writing code for, say the PS5, will know the exact set of instructions in the diagram above that the Zen 2 core supports, and can write code using intrinsics for those instructions without worrying about the rest. If you want vector-heavy code to run well across a wide range of hardware on PC, you'll probably have code that has a lot of switch statements with intrinsics for whichever of the 31 different feature sets you want to support. An ARM chip like TX1 or T239 will then need different vector intrinsics from an x86 chip.
Incidentally, as the discussion of whether Nintendo will or should use newer ARM CPUs like the A710 or A715 has come up now and again, this is probably the best argument to do so, because of the SVE2 vector instructions supported by ARMv9 CPUs from the A710 onwards. These are independent of vector length, which substantially simplifies the problem of optimising for different architectures (although ARM was already a lot simpler than the x86 diagram above), but they're also much better for auto-vectorisation, where the compiler finds ways that scalar code (mostly for loops) can be mapped to vector instructions to increase performance. Game developers would still use vector intrinsics wherever they can, but SVE2 would make their job a bit easier when it comes to having a single set of intrinsics which will work well across a wider range of hardware, and allowing the compiler to catch some additional vectorisation opportunities which the developer may have missed.






 . But if 128 gb carts are reasonably affordable I say why not.
. But if 128 gb carts are reasonably affordable I say why not.