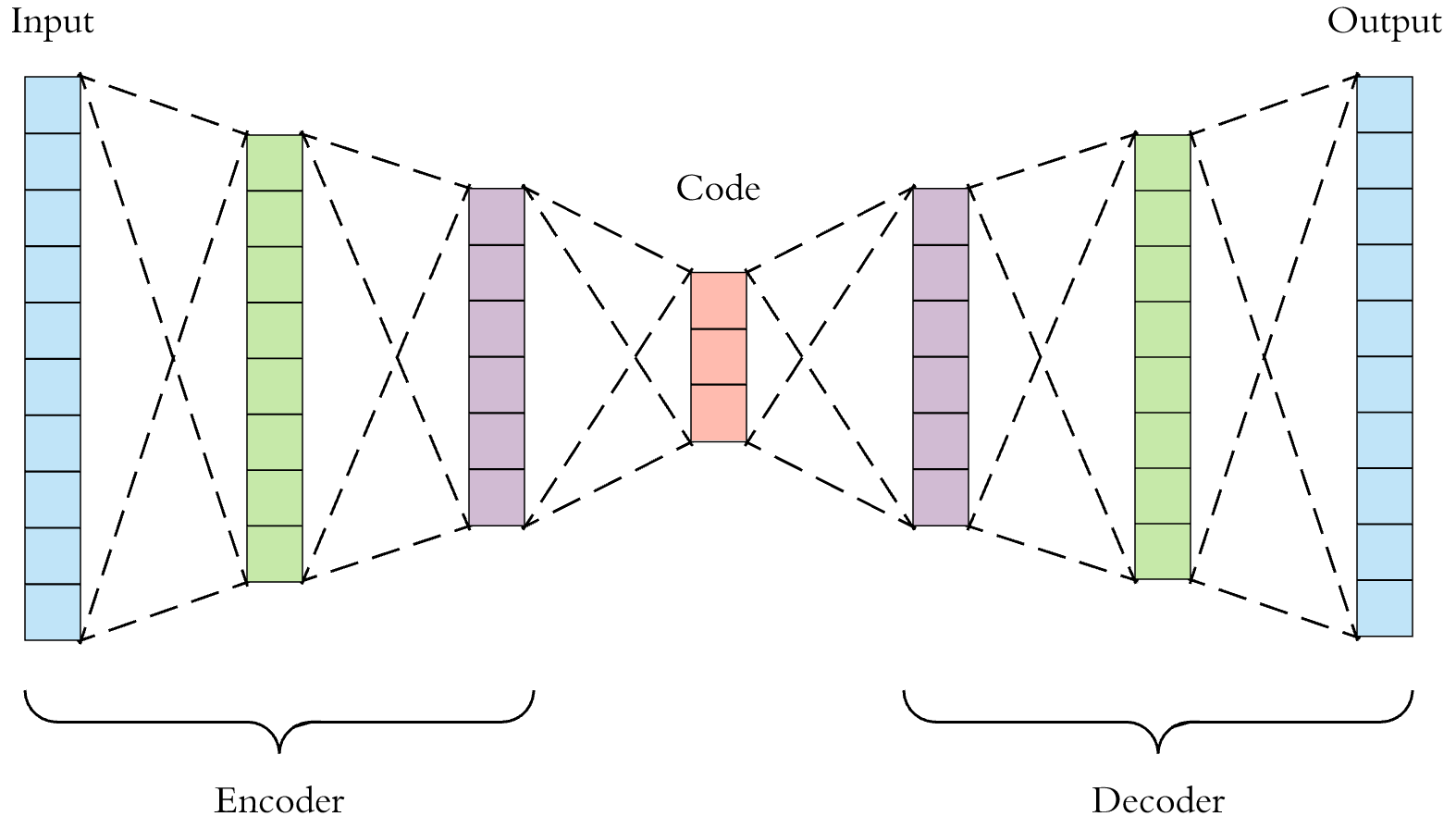
Ultra performance is good at reducing rendering cost, but the computational cost of DLSS itself is mostly dictated by output resolution. This is all assuming that it’s a convolutional neural network; Nvidia has said ‘convolutional autoencoder,’ but that’s just a specific genre of CNN architecture that looks like this:
Or in the case of the
Facebook neural supersampling paper written by Anton Kaplanyan, who Intel just poached for XeSS, like this:
I’ve posted about this in more detail on Era, but the computational cost of a CNN is proportional to pixel resolution, and the reconstruction has to happen at the output resolution.
Gory details:
the computational cost going from one layer to the next layer for a CNN with zero padding, a step size of 1, and a 3x3 filter is the cost of doing a dot product with (3 * 3 * number of channels in the current layer) elements in whatever precision you are working in times (height in pixels * width in pixels * number of channels in the next layer * cost of activation).
The Kaplanyan method also uses two other CNNs: one to weight previous frames at output resolution, and one to learn features at input resolution. The latter or its equivalent in DLSS is a place where you could have some savings in ultra performance mode, but the reconstruction network is the bottleneck by far in the case of the Facebook/Kaplanyan paper. If that holds true for DLSS, running the same architecture at 4K output resolution would approach being twice as expensive as at 1440p.
(I am assuming here that ultra performance uses the same neural network(s) as the other modes and that only resolution scales.)
I believe that someone on Era made an estimate of how long it would take DLSS to complete on a few potential versions of Dane, but I can’t find the post right now and don’t remember the poster. In any case, the gist was that reconstructing at 4K with DLSS may consume a significant portion of the frame time.
The post that ILikeFeet shared makes the point that DLSS likely could be even better at reconstruction if it were deeper, but that Nvidia is potentially limiting the number of layers to hit their 2 ms target. Similarly, the way to optimize DLSS for an even tighter performance budget would be to do the opposite and make the network even shallower at risk of somewhat decreasing the reconstruction quality.
Lovelace could indeed have some secret sauce that further leverages parallelization or sparsity, but there’s still a hearty chunk of calculations to do at the end of the day.







 . Nintendo has no problem going against the grain and whatever is considered an “industry standard.”
. Nintendo has no problem going against the grain and whatever is considered an “industry standard.”