While we're in a bit of a waiting period, Thraktor, I forgot, but were the comparisons you made with Geekbench scores between A78 and desktop Zen 2 or the 4700S?
I vaguely remember the A78 falling a bit behind in IPC, but I'm sitting here thinking it can punch up a bit in gaming specifically thanks to differences in inter-core latency due to topology, a la Skylake vs Zen 2.
To expand on the above for the readers:
Zen 2 organizes its cores into groups of 4 called Core Complexes (CCX). Within a given CCX, all 4 cores are directly linked to each other, leading to fantastic latency when a core has to communicate to another within the same CCX. However, if you need to communicate with another CCX, jumping out to IO and then into the other one adds a relatively noticeable amount of time.
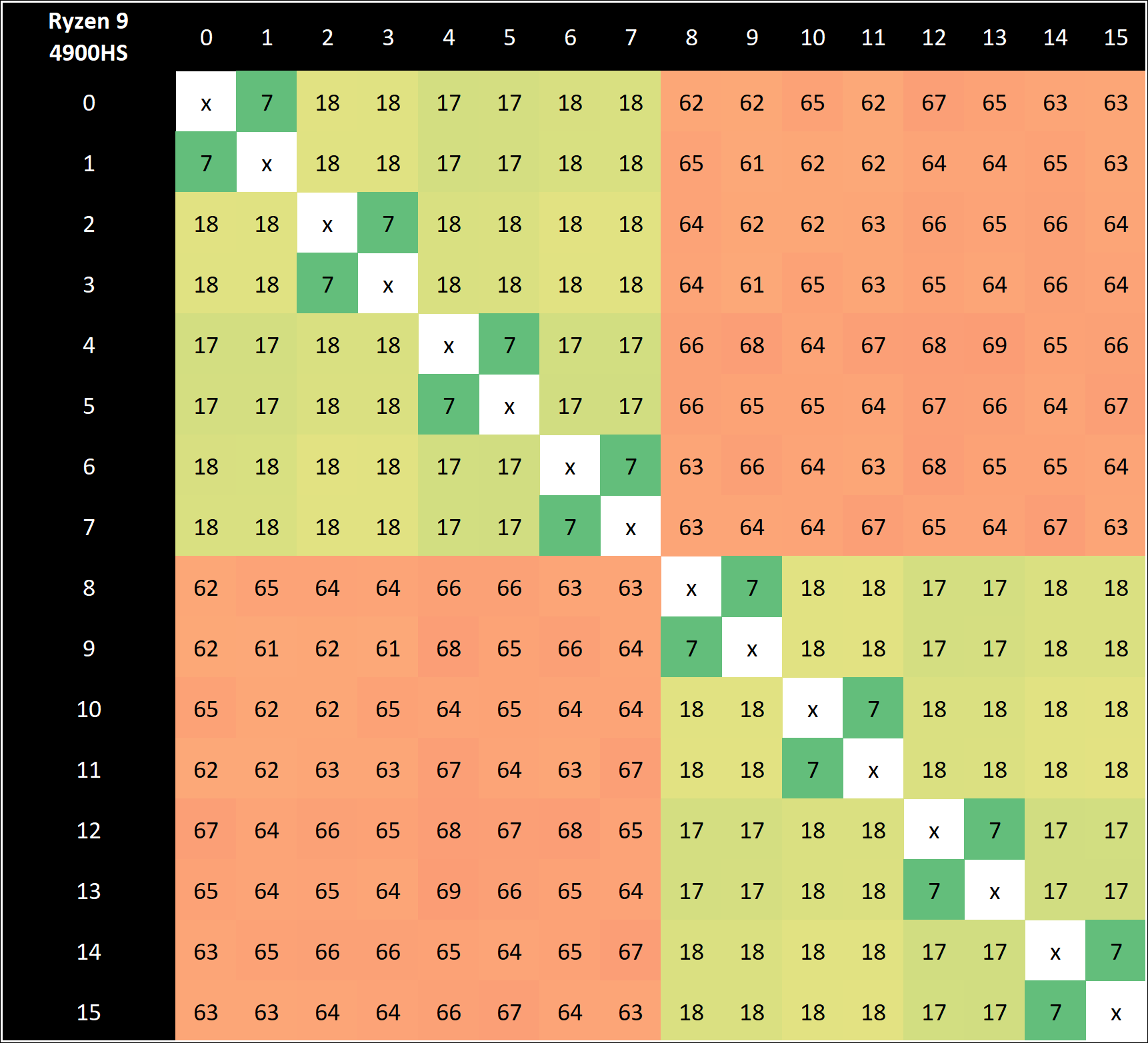
For example, this chart gives us inter-core latencies for an 8 core Renoir (Zen 2, monolithic APU, which ought to be the same category as the PS5/Xbox Series CPU):
The 7 nanoseconds is for two threads on the same core. 17-18 ns is for different cores, same CCX. 60's ns is for different CCXs.
Btw, desktop Zen 2 has higher inter-CCX latency by... ~20 ns maybe for the same CCD (Core Complex Die; physical piece that contains 2 CCX) due to presumably the chiplet setup increasing distances to the IO relative to monolithic. And further higher for different CCD due to increased distance and maybe another stop along the way. But, desktop Zen 2 has 16 MB of L3 cache per CCX compared to the monolithic Zen 2 APUs having 4 MB per CCX. And the Geekbench results for the 4700S report 4 MB x 2 for L3, so it's like the other Zen 2 APUs.
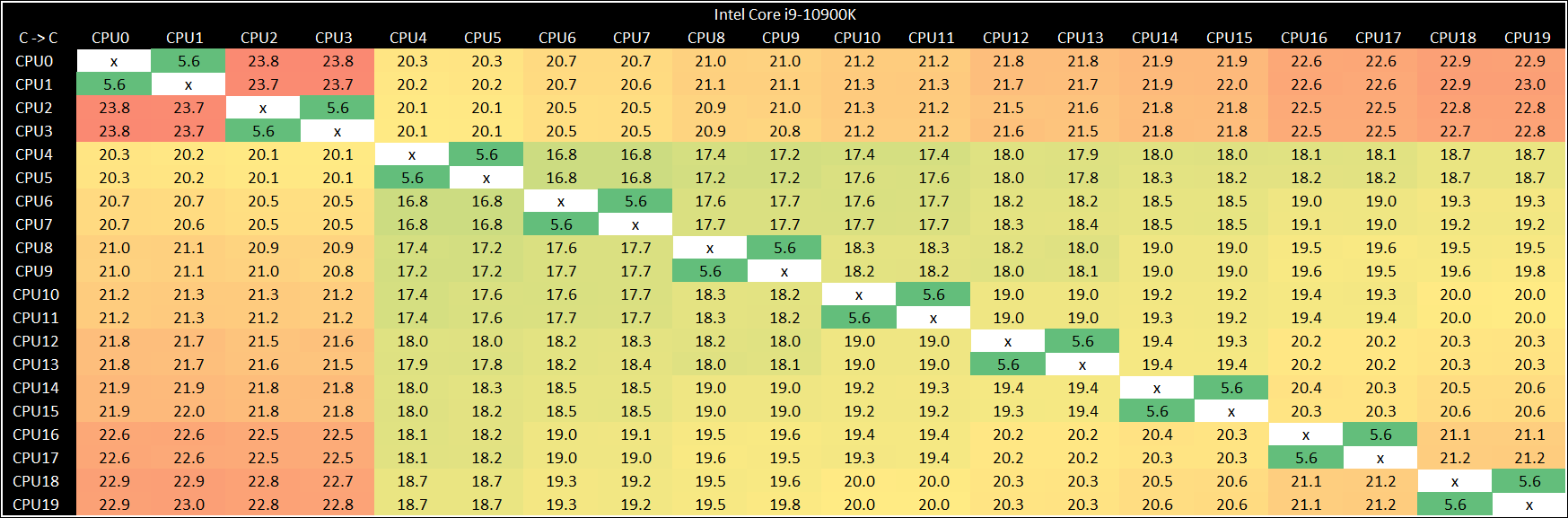
IIRC, while Zen 2 pulled ahead in productivity, AMD couldn't take the gaming crown yet. I personally think that Skylake was able to maintain the edge there due to better average latency (thanks to the glorious bi-directional ring bus).
Comet Lake 10900k (10 Skylake cores, so the loop is being stretched to its limits):
Think of a ring bus like... a train or subway line going in a loop, with each core being a stop/station. Bi-directional would be having one track/line going one direction, one track/line going the other direction.
Now, to relate it back ARM...
So, as far as I'm aware, ARM never disclosed the topology of the previous version of the DynamIQ Shared Unit. But when they introduced the ARMv9 stuff last year, they did describe the new version of the DSU as a dual bi-directional ring structure; two rings of 4 cores each, with two locations where the rings connect to each other. And apparently they claimed to try to keep latencies as low as the previous version.
...and to satisfy my own curiosity,
this article claims that the previous DSU was a hybrid crossbar of some sort. And it also describes the previous DSU as having 'very low latencies, to begin with'.
Crossbar's basically a grid, with lines/connections running vertically and horizontally. A crossbar with a max of 8 cores would probably be 2 rows/4 columns, or 4 rows/2 columns, I suppose?