
D
Deleted member 887
Guest
It is 100% future frames.It's surely intermediate frames rather than future ones, or else there would be horrible issues any time you panned/rotated the camera quickly, right?
It is 100% future frames.It's surely intermediate frames rather than future ones, or else there would be horrible issues any time you panned/rotated the camera quickly, right?
I believe their own documentation has confirmed that they are generating tweens.If it were just creating in-between frames from two finished frames, it would be little different than a higher quality version of what most TVs already offer. It would also necessarily add image latency, since you'd need to render frame A to create in-between frame A-1, and hold back frame A another 1/60 or 1/120 of a second or whatever the case may be.
more than a hope was a curiosityDon’t get your hopes up.

I see, thank youI've been going through the recent Linux drops for Tegra, where they've added support for Drake. Drake's OFA driver - the OFA is what DLSS 3.0 uses for its special sauce - is the same as Orin's, unlike some other parts of T239, where it overrides the Orin driver.
So as close to 0% as we can imagine at this point.

Linux updates:
Interesting Timing Bits: Drake Linux was being developed on software simulation in January of last year. In April, there were a set of Drake related updates that seem to indicate that actual engineering samples were being produced. In July, the code was branched to consolidate Orin changes for public release so that Drake work could continue. Any further references to Drake in the various public repos since are entirely updates to places where Drake share's Orin's driver, but needs a Drake specific exception (like the cpu-freq updates). This is likely so that there is a One True Source for Orin drivers and Drake dev can simply pull it from upstream, rather than maintaining multiple forks at Nvidia that are constantly cross merging.
I take it to mean that they're using data from frame A and B to create B+1. If the machinery can see how things changed from from A to B, it can continue those same motions and make a 150% version while also working on frame C.I believe their own documentation has confirmed that they are generating tweens.
Or at least that they require two frames to begin frame generation, maybe?
Unless I am vastly misunderstanding, they just need to frames to seed the process. They're absolutely generating future frames - specifically they call out generating the next frame entirely on the GPU while the CPU is totally bottlenecked.I believe their own documentation has confirmed that they are generating tweens.
Or at least that they require two frames to begin frame generation, maybe?
I haven't heard anything about using ai to decompress textures. but Nvidia has tools for using the gpu to decompress assetsWould it be possible to use some DLSS-like technology (developed by NVidia or even NERD) to "decompress" textures? Something much more efficient than we have today.
It would be interesting to get around the problems of bandwidth, and internal memory of the console and cartridges.
You need two frames of data to run the Optical Flow Analyzer to detect motion vectors, I believeI take it to mean that they're using data from frame A and B to create B+1. If the machinery can see how things changed from from A to B, it can continue those same motions and make a 150% version while also working on frame C.
I take it to mean that they're using data from frame A and B to create B+1. If the machinery can see how things changed from from A to B, it can continue those same motions and make a 150% version while also working on frame C.
I understood it this way, but their own visual aid shows alternating upscaled and generated frames, so I think they've muddied the waters a bit.Unless I am vastly misunderstanding, they just need to frames to seed the process. They're absolutely generating future frames - specifically they call out generating the next frame entirely on the GPU while the CPU is totally bottlenecked.
The target is extreme high frame rate games. 60FPS+ starts to exceed human reaction time for most folks. The speed of your neurons from your eye to your hand is slower than a frame rate update, but you can absolutely perceive the smoothness visually. So if your game engine is running at 60FPS you're probably find for human reaction, but if you're getting 120 frames in smoothness, that's the win.
As folks point out, this implies perceived latency in moving the camera rapidly, but NVidia claims some integration with their latency tools so I'm waiting for a breakdown before speculating heavily.
OK let me phrase this better: Nintendo funds, the R&D for Nvidia to design a customized chip just for them, they use their AI supercomputer to basically make a chip.You are correct, of course, but I think we're stuck with that no matter what. Ampere-B has been on Samsung 8nm the entire time, Orin was built on 8nm, and we know T239 shares design with T234. There is likely not a cost advantage porting to TSMC now over porting to TSMC later, because it's going to be a port either way, as opposed to being built fresh on TSMC. I’ll
Of course, Ampere-A was already on TSMC 7nm, and the ARM uses custom verilog libraries to support a wide range of nodes out of the box for their CPUs. At least some of the groundwork was laid well before Drake dev started

We know NVN2 was running on Orin at some point, yes? And that Orin doesn't have RT hardware? This tracks with devkits having "RT problems" which we had heard in the rumor mill beforeengineering samples being out in April 2021 is interesting. either that means devs were working on simulated kits or they were working on analogues. I would bet on there being orin-based kits before then
DLSS1 is just plain image upscaling, and could be used on textures I suppose. Lots of people make mods for PC games where they put the textures through some form of machine upscaling for cheap improved results. But in that case it's still being treated like a regular texture file in the end, taking up more space and bandwidth. Making it instead an alternative to bilinear filtering or whatever for final use of textures... how feasible or costly that is is beyond my layman's knowledge.Would it be possible to use some DLSS-like technology (developed by NVidia or even NERD) to "decompress" textures? Something much more efficient than we have today.
It would be interesting to get around the problems of bandwidth, and internal memory of the console and cartridges.
Sure.I understood it this way, but their own visual aid shows alternating upscaled and generated frames, so I think they've muddied the waters a bit.
As I understand it Nvidia does have AI tools that upres existing textures, though I'm not sure that type of thing can be done on the fly which would be necessary for decompressing textures like you seem to be suggesting.Would it be possible to use some DLSS-like technology (developed by NVidia or even NERD) to "decompress" textures? Something much more efficient than we have today.
It would be interesting to get around the problems of bandwidth, and internal memory of the console and cartridges.
they refer to them as intermediate frames. but I suppose it's a matter of perspectiveIt is 100% future frames.
Ever since the hack, my internal goalpost for a 15 watt device that I'd be very happy with was pretty much 'take a PS4 Pro, double the CPU power, and kick the RAM amount up a notch'. Approximately a midpoint between PS4 and PS5. Shouldn't be hard to clear at this rate!ES6 being Xbox exclusive is more likely going to be a blocker than Switch 2 performance I’m guessing. Otherwise 100% with you. I’ve been thinking for quite some time that around PS4 Pro quality on Switch is my dream hardware for at least another 5-10 years.
RAM efficiency, in the energy per bit sense, will improve from a combination of nodes and moving to LPDDR5. Buuut, it's highly unlikely that the energy efficiency has improved to the point of compensating for up to four times the amount of bits being moved. I think that with the amounts Thraktor estimated before, at maximum usage, we're looking at somewhere around +1 watt being used, give or take some tenths.I'd really be wary to assume they'll increase the battery size. I think it's safer to stick with the ~4-5W range Erista had for estimations.
This Switch should see improvements in screen power efficiency at the very least. I'm not sure about RAM or storage efficiency.
Not quite true, look at the post I quoted.
 )
)April of this year. To be clear, the indication is that the folks developing the Linux drivers had access to hardware at this time. It is unclear at what point in the pipeline developing Linux drivers was at.By April, you mean April of this year, not last?
Orin does have RT cores, but Nvidia doesn't advertise them. my assumption with the RT problem is that the games aren't too optimized yet. maybe devs were using similar settings as PC/consoles, maybe the SDK isn't running as well as it could, maybe this was before dlss. there's too much unknown to make a conclusion other than what they did test ran through batteryWe know NVN2 was running on Orin at some point, yes? And that Orin doesn't have RT hardware? This tracks with devkits having "RT problems" which we had heard in the rumor mill before
I thought Falcon was replaced by Peregrine since Ampere?Falcon/TSEC: FAst Logic CONtroller, used in lots of things. Drake's seems to be different from Orin. A Falcon is used in TSEC, the Tegra Security Coprocessor in the X1, which accelerates cryptography and is part of the secure OS boot process that prevents the Switch from being jailbroken
What would thd draw be with 4SMs then? Compared to the 8 and 16 that is.I just had a play around with the Jetson power tool myself, and I'm getting quite different estimates than were posted before.
For the GPU, my methodology was to turn off the DVA/PVA, etc., set the CPU to a fixed value, and compare the power consumption with the GPU turned off entirely to the power consumption at each GPU clock speed for 4 TPC (8 SM) and 8 TPC (16 SM) configurations. Then for each clock, I took the mid-point of the 4 TPC and 8 TPC power consumption, and subtracted the power with the GPU turned off. I set the GPU load level to high for all these tests. I feel this is a reasonable way to isolate the GPU power consumption and estimate it in a 12 SM configuration.
The power consumption figures I got for the GPU with 12 SMs are:
420.75MHz - 5.70W
522.75MHz - 6.80W
624.75MHz - 8.65W
726.75MHz - 10.85W
828.75MHz - 13.20W
930.75MHz - 16.35W
1032.75MHz - 19.90W
1236.75MHz - 29.35W
These probably overestimate the power consumption of an 8nm Drake GPU by a bit, as it uses smaller tensor cores, has fewer ROPs, and should have some small power savings by using only a single GPC rather than two. Still, I wouldn't expect the power consumption to be significantly lower than this. A few months ago I made some rough estimates of power consumption of Ampere on 8nm by measuring my RTX 3070 and scaling from there, and I got a figure of 16.1W for 12 SMs at 1155MHz. This was a very crude estimate (just take the reported power consumption from GPU-Z and divide by the number of SMs), and seems to come in a bit lower than we see above. I'd err on the side of trusting Nvidia's official tool for estimating Orin power consumption over my rough estimate based on a GPU 4x as big, though.
I believe the original Switch's GPU consumed somewhere around 3W in portable mode, which means we're already pushing things at the base clock of 420MHz. Even if Drake comes down to about 5W at 420MHz from the smaller tensor cores and other optimisations, that's still a big increase. It's impossible to say how power consumption behaves at lower clocks, and maybe they could squeeze it in at the same 384MHz clock as the original Switch, but my guess is if Nvidia doesn't clock below 420MHz in any configuration, it's because it's not efficient to do so. I'm still of the opinion that running a full 12 SM GPU on 8nm isn't feasible in handheld mode for a device the same size as the current Switch, which means either disabling SMs in handheld mode, or a different manufacturing process.
On the docked side of things, they're more limited by cooling than power consumption, and a 768MHz clock seems reasonable with a similar cooling set-up to the original Switch, if running a bit hotter. They could possibly push up higher to 900MHz-1GHz or so if they really wanted to, but it's more a question of Nintendo's tolerance for a more expensive cooling setup and/or more fan noise than a technical limitation.
For the CPU, as it's not possible to turn the CPU off entirely, I simply took the difference between the 4 core and 12 core CPU configuration for each clock, again with the CPU load level set to high. As a bit of a sense-check, I also checked the reported power consumption for each clock on an 8 core configuration, and validated that the difference in power draw between 4 and 8 cores was approximately the same as between 8 and 12 cores. This is true typically to within 0.1W, so I think it's reasonable to assume the power cost is linear with respect to the number of clusters activated (ie if going from 1 to 2 clusters adds the same amount of power consumption as moving from 2 to 3, then we can infer that going from 0 to 1 cluster of cores costs a similar amount).
The figures I got for an 8 core CPU are as follows:
1113.6MHz - 2.2W
1267.2MHz - 2.5W
1497.6MHz - 3.1W
1651.2MHz - 3.8W
1728.0MHz - 4.1W
1881.6MHz - 4.9W
2035.2MHz - 5.8W
2188.8MHz - 7.1W
CPU power consumption on Drake might be a bit lower due to using a single cluster and potentially less cache, but I would expect only pretty small differences here. Compared to the GPU, though, I don't think there's as big an issue. The CPU on the original Switch consumed a bit under 2W, so Nintendo could clock a bit higher than the old 1GHz. While ~1.1GHz or so might not sound like much, an 8 core A78 clocked at 1.1GHz (with 7 cores for games) is still a huge increase over 4 A57 cores (with 3 for games) at 1GHz. If they push the power draw of the CPU up a bit (which I feel is more likely than increasing handheld GPU power draw), then at 3W they could get up to around 1.5GHz, which would put them in a pretty nice spot.
The CPU side of things is a bit better than I expected, to be honest. You're obviously not going to clock 8 A78s up to 2GHz+ on 8nm in Switch's form-factor, but they don't have to clock them down to oblivion to get them to work. It would still be comfortably more capable than PS4/XBO's CPUs in a portable device while on an old manufacturing process, which isn't a bad position to be in.
the problem with going even lower is that Nvidia faces stiff competition from AMD and Intel. I don't think the MX570 is that widely adopted@Thraktor those seem MUCH more in line with the Orin spec figures, and desktop Ampere in general. If they could really match the other figures, we might be seeing a whole new range of 8NM GPUs for laptops etc using whatever witchcraft that would have been.
This sounds like extrapolation to me. You render the current frame N using the super resolution network, calculate the optical flow field between frame N and N-2, and pass that to the neural network, which internally predicts how that flow field will evolve in the next frame.The DLSS Frame Generation convolutional autoencoder takes 4 inputs – current and prior game frames, an optical flow field generated by Ada’s Optical Flow Accelerator, and game engine data such as motion vectors and depth.
For each pixel, the DLSS Frame Generation AI network decides how to use information from the game motion vectors, the optical flow field, and the sequential game frames to create intermediate frames. By using both engine motion vectors and optical flow to track motion, the DLSS Frame Generation network is able to accurately reconstruct both geometry and effects, as seen in the picture below.
I just had a play around with the Jetson power tool myself, and I'm getting quite different estimates than were posted before.
For the GPU, my methodology was to turn off the DVA/PVA, etc., set the CPU to a fixed value, and compare the power consumption with the GPU turned off entirely to the power consumption at each GPU clock speed for 4 TPC (8 SM) and 8 TPC (16 SM) configurations. Then for each clock, I took the mid-point of the 4 TPC and 8 TPC power consumption, and subtracted the power with the GPU turned off. I set the GPU load level to high for all these tests. I feel this is a reasonable way to isolate the GPU power consumption and estimate it in a 12 SM configuration.
The power consumption figures I got for the GPU with 12 SMs are:
420.75MHz - 5.70W
522.75MHz - 6.80W
624.75MHz - 8.65W
726.75MHz - 10.85W
828.75MHz - 13.20W
930.75MHz - 16.35W
1032.75MHz - 19.90W
1236.75MHz - 29.35W
These probably overestimate the power consumption of an 8nm Drake GPU by a bit, as it uses smaller tensor cores, has fewer ROPs, and should have some small power savings by using only a single GPC rather than two. Still, I wouldn't expect the power consumption to be significantly lower than this. A few months ago I made some rough estimates of power consumption of Ampere on 8nm by measuring my RTX 3070 and scaling from there, and I got a figure of 16.1W for 12 SMs at 1155MHz. This was a very crude estimate (just take the reported power consumption from GPU-Z and divide by the number of SMs), and seems to come in a bit lower than we see above. I'd err on the side of trusting Nvidia's official tool for estimating Orin power consumption over my rough estimate based on a GPU 4x as big, though.
I believe the original Switch's GPU consumed somewhere around 3W in portable mode, which means we're already pushing things at the base clock of 420MHz. Even if Drake comes down to about 5W at 420MHz from the smaller tensor cores and other optimisations, that's still a big increase. It's impossible to say how power consumption behaves at lower clocks, and maybe they could squeeze it in at the same 384MHz clock as the original Switch, but my guess is if Nvidia doesn't clock below 420MHz in any configuration, it's because it's not efficient to do so. I'm still of the opinion that running a full 12 SM GPU on 8nm isn't feasible in handheld mode for a device the same size as the current Switch, which means either disabling SMs in handheld mode, or a different manufacturing process.
On the docked side of things, they're more limited by cooling than power consumption, and a 768MHz clock seems reasonable with a similar cooling set-up to the original Switch, if running a bit hotter. They could possibly push up higher to 900MHz-1GHz or so if they really wanted to, but it's more a question of Nintendo's tolerance for a more expensive cooling setup and/or more fan noise than a technical limitation.
For the CPU, as it's not possible to turn the CPU off entirely, I simply took the difference between the 4 core and 12 core CPU configuration for each clock, again with the CPU load level set to high. As a bit of a sense-check, I also checked the reported power consumption for each clock on an 8 core configuration, and validated that the difference in power draw between 4 and 8 cores was approximately the same as between 8 and 12 cores. This is true typically to within 0.1W, so I think it's reasonable to assume the power cost is linear with respect to the number of clusters activated (ie if going from 1 to 2 clusters adds the same amount of power consumption as moving from 2 to 3, then we can infer that going from 0 to 1 cluster of cores costs a similar amount).
The figures I got for an 8 core CPU are as follows:
1113.6MHz - 2.2W
1267.2MHz - 2.5W
1497.6MHz - 3.1W
1651.2MHz - 3.8W
1728.0MHz - 4.1W
1881.6MHz - 4.9W
2035.2MHz - 5.8W
2188.8MHz - 7.1W
CPU power consumption on Drake might be a bit lower due to using a single cluster and potentially less cache, but I would expect only pretty small differences here. Compared to the GPU, though, I don't think there's as big an issue. The CPU on the original Switch consumed a bit under 2W, so Nintendo could clock a bit higher than the old 1GHz. While ~1.1GHz or so might not sound like much, an 8 core A78 clocked at 1.1GHz (with 7 cores for games) is still a huge increase over 4 A57 cores (with 3 for games) at 1GHz. If they push the power draw of the CPU up a bit (which I feel is more likely than increasing handheld GPU power draw), then at 3W they could get up to around 1.5GHz, which would put them in a pretty nice spot.
The CPU side of things is a bit better than I expected, to be honest. You're obviously not going to clock 8 A78s up to 2GHz+ on 8nm in Switch's form-factor, but they don't have to clock them down to oblivion to get them to work. It would still be comfortably more capable than PS4/XBO's CPUs in a portable device while on an old manufacturing process, which isn't a bad position to be in.
Is it possible to test with 2 TCPs? If so, would we get a closer approximation of 12 SM in a single GPC if we add the difference between 4 and 8 SM to 8 SM results?These probably overestimate the power consumption of an 8nm Drake GPU by a bit, as it uses smaller tensor cores, has fewer ROPs, and should have some small power savings by using only a single GPC rather than two.
Yuzu devs are allowed to (and do) have a buggy product. Nintendo doesn't have that luxury for a system that costs hundreds. That's all there is to it.So Yuzu devs are expected to clown Nintendo? Huh. Neat.
Yeah it's clear there's some nonlinearity happening with such a large discrepancy over the other numbers (was it adding the 4SM number to 8SM number or multiplying the 16SM number by 0.75?) so it would be interesting to see how much we could narrow down these rough estimates.What would thd draw be with 4SMs then? Compared to the 8 and 16 that is.
This can probably be charted on a graph and scaled appropriately to see what it should be about for the in-between
Yes I was about to post the same. 'Current and prior' 100% refers to rendered frames only, because those rendered frames are the inputs. so it's a question of 'does 'current' also mean something else in relation to final frame order', which I don't think it necessarily does. I think it is more sensible to slot in the generated frame between the two inputs, rather than after, as it will undoubtedly look better. And the latency will typically be better, at least compared to ... uh brute forcing full 4K, which Nvidia unhelpfully offers as the comparison. (i'd much prefer a comparison to DLSS 2.1!)At this point, idk. This all hinges on how Nvidia is defining the “current frame;” if all they mean is “the frame being rendered,” then the distinction is a moot point, and it’s frame interpolation. I’m sure there will be clarification when the press embargo lifts.
So then if I were take ~2.23 Ghz@1 watt, then apply some more napkin math (half the frequency for quarter the power and all that jazz)...@oldpuck
Hmm, here's my stab at the A78 power usage on Samsung 8nm question.
First off, I'm assuming that Samsung's 4LPP is comparable to TSMC N5, so I'm subbing in 3 Ghz@1 watt for 4LPP. I actually don't think that's the case, but I need a number to start with, and hey, maybe I was wrong and 4LPP actually is comparable to N5. So consider this an optimistic/best case estimation.
Then, I take what Samsung claims in this slide from July 20221 at face value. Like some others here, that's not necessarily something I prefer to do, but for this exercise, fine.
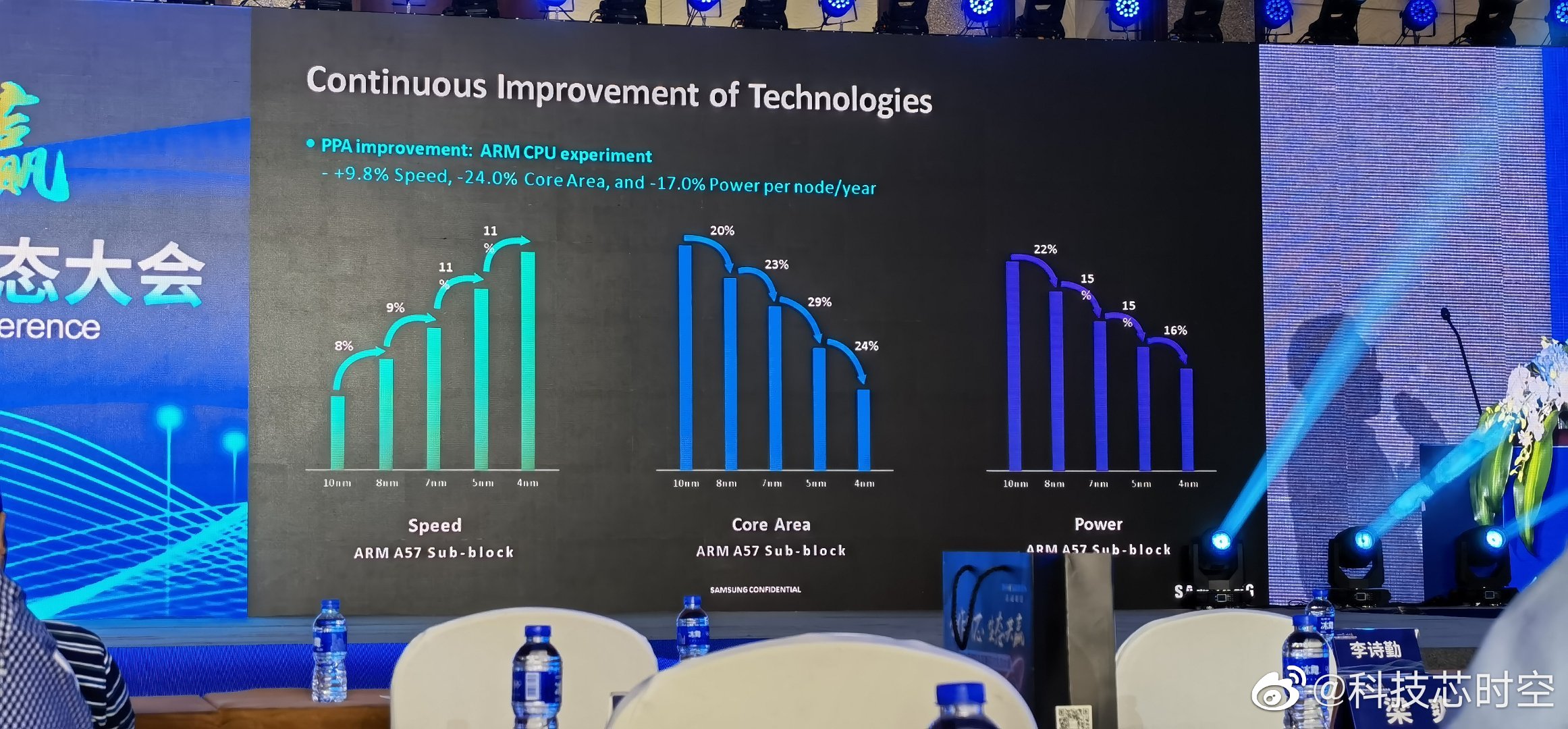
Working backwards from 4LPP to get to 8LPP, take the 3 Ghz@1 watt, then go 3/(1.11*1.11*1.09) ~= 2.23 Ghz@1 watt.
Given that, my guess for how much power 1.7 Ghz would require would then be...
2.23/1.7 ~= 1.31 (ratio of the two frequencies)
1.31^2 ~= 1.73 (the relative increase in power to go from 1.7 Ghz to ~2.23 Ghz)
1/1.73 ~= 0.58
So, at best, 0.58 watts to get a single A78 to 1.7 ghz on Samsung's 8 nm node. More likely to be a bit higher than that. Probably fair to round it up to 0.6 watts?
The Yuzu development team is also larger than NERD, isn't legally reusable by Nintendo, and based on SLOC alone is a 10+ million dollar project for the core emulator alone.Yuzu devs are allowed to (and do) have a buggy product. Nintendo doesn't have that luxury for a system that costs hundreds. That's all there is to it.
@Thraktors numbers are also in the ballpark of my handwavy Orin math as well, if somewhat better. Which lands me back where I was a month ago "8nm feasible, but man, it's pushing it"So then if I were take ~2.23 Ghz@1 watt, then apply some more napkin math (half the frequency for quarter the power and all that jazz)...
~1.116 [email protected] watt. Still a bit better than what Thraktor got above (8x 1.113Ghz totaling 2.2 watts, so 1x 1.113 [email protected] watt). But I did not expect this handwavey crap to land anywhere near that close.
Honestly, I feel that it may be too much still.I just had a play around with the Jetson power tool myself, and I'm getting quite different estimates than were posted before.
For the GPU, my methodology was to turn off the DVA/PVA, etc., set the CPU to a fixed value, and compare the power consumption with the GPU turned off entirely to the power consumption at each GPU clock speed for 4 TPC (8 SM) and 8 TPC (16 SM) configurations. Then for each clock, I took the mid-point of the 4 TPC and 8 TPC power consumption, and subtracted the power with the GPU turned off. I set the GPU load level to high for all these tests. I feel this is a reasonable way to isolate the GPU power consumption and estimate it in a 12 SM configuration.
The power consumption figures I got for the GPU with 12 SMs are:
420.75MHz - 5.70W
522.75MHz - 6.80W
624.75MHz - 8.65W
726.75MHz - 10.85W
828.75MHz - 13.20W
930.75MHz - 16.35W
1032.75MHz - 19.90W
1236.75MHz - 29.35W
These probably overestimate the power consumption of an 8nm Drake GPU by a bit, as it uses smaller tensor cores, has fewer ROPs, and should have some small power savings by using only a single GPC rather than two. Still, I wouldn't expect the power consumption to be significantly lower than this. A few months ago I made some rough estimates of power consumption of Ampere on 8nm by measuring my RTX 3070 and scaling from there, and I got a figure of 16.1W for 12 SMs at 1155MHz. This was a very crude estimate (just take the reported power consumption from GPU-Z and divide by the number of SMs), and seems to come in a bit lower than we see above. I'd err on the side of trusting Nvidia's official tool for estimating Orin power consumption over my rough estimate based on a GPU 4x as big, though.
I believe the original Switch's GPU consumed somewhere around 3W in portable mode, which means we're already pushing things at the base clock of 420MHz. Even if Drake comes down to about 5W at 420MHz from the smaller tensor cores and other optimisations, that's still a big increase. It's impossible to say how power consumption behaves at lower clocks, and maybe they could squeeze it in at the same 384MHz clock as the original Switch, but my guess is if Nvidia doesn't clock below 420MHz in any configuration, it's because it's not efficient to do so. I'm still of the opinion that running a full 12 SM GPU on 8nm isn't feasible in handheld mode for a device the same size as the current Switch, which means either disabling SMs in handheld mode, or a different manufacturing process.
On the docked side of things, they're more limited by cooling than power consumption, and a 768MHz clock seems reasonable with a similar cooling set-up to the original Switch, if running a bit hotter. They could possibly push up higher to 900MHz-1GHz or so if they really wanted to, but it's more a question of Nintendo's tolerance for a more expensive cooling setup and/or more fan noise than a technical limitation.
For the CPU, as it's not possible to turn the CPU off entirely, I simply took the difference between the 4 core and 12 core CPU configuration for each clock, again with the CPU load level set to high. As a bit of a sense-check, I also checked the reported power consumption for each clock on an 8 core configuration, and validated that the difference in power draw between 4 and 8 cores was approximately the same as between 8 and 12 cores. This is true typically to within 0.1W, so I think it's reasonable to assume the power cost is linear with respect to the number of clusters activated (ie if going from 1 to 2 clusters adds the same amount of power consumption as moving from 2 to 3, then we can infer that going from 0 to 1 cluster of cores costs a similar amount).
The figures I got for an 8 core CPU are as follows:
1113.6MHz - 2.2W
1267.2MHz - 2.5W
1497.6MHz - 3.1W
1651.2MHz - 3.8W
1728.0MHz - 4.1W
1881.6MHz - 4.9W
2035.2MHz - 5.8W
2188.8MHz - 7.1W
CPU power consumption on Drake might be a bit lower due to using a single cluster and potentially less cache, but I would expect only pretty small differences here. Compared to the GPU, though, I don't think there's as big an issue. The CPU on the original Switch consumed a bit under 2W, so Nintendo could clock a bit higher than the old 1GHz. While ~1.1GHz or so might not sound like much, an 8 core A78 clocked at 1.1GHz (with 7 cores for games) is still a huge increase over 4 A57 cores (with 3 for games) at 1GHz. If they push the power draw of the CPU up a bit (which I feel is more likely than increasing handheld GPU power draw), then at 3W they could get up to around 1.5GHz, which would put them in a pretty nice spot.
The CPU side of things is a bit better than I expected, to be honest. You're obviously not going to clock 8 A78s up to 2GHz+ on 8nm in Switch's form-factor, but they don't have to clock them down to oblivion to get them to work. It would still be comfortably more capable than PS4/XBO's CPUs in a portable device while on an old manufacturing process, which isn't a bad position to be in.
I think there's more work involved with transitioning from Samsung's 8N process node to TSMC's 4N process node for a die shrink since Samsung's 8N process node uses DUV lithography and TSMC's 4N process node uses EUV lithography. So I imagine Nintendo and Nvidia are probably going to have to redesign Drake with EUV lithography and TSMC's IPs in mind if going from Samsung's 8N process node to TSMC's 4N process node for a die shrink.You are correct, of course, but I think we're stuck with that no matter what. Ampere-B has been on Samsung 8nm the entire time, Orin was built on 8nm, and we know T239 shares design with T234. There is likely not a cost advantage porting to TSMC now over porting to TSMC later, because it's going to be a port either way, as opposed to being built fresh on TSMC.
the performance difference between Samsung 8nm and TSMC N7/N6 at the same power is not double, can we maybe not go full negative exaggeration on thisLet's hope for the best case scenario and assume that Nintendo has chosen a more recent process node. But if not, then I guess a Drake with half the power is still OK.
I said double because Thraktor supports the idea that a GPU on 8nm would have half its cores disabled in portable mode.the performance difference between Samsung 8nm and TSMC N7/N6 at the same power is not double, can we maybe not go full negative exaggeration on this
ThereI said double because Thraktor supports the idea that a GPU on 8nm would have half its cores disabled in portable mode.
It sounds like the same thing as the first to me, not sure what part makes you think frame N+2 comes into play?Second:
This paragraph sounds like interpolation. In that loop, you would render frame N+2 using super resolution, calculate the optical flow field between frame N and N+2, and pass that to the neural network.
Look better, yes. Taking a full second to render a frame also looks better than doing so dozens of times a second. But for real-time functionality like a game, being done sooner is important.I think it is more sensible to slot in the generated frame between the two inputs, rather than after, as it will undoubtedly look better.
I don't think introducing variable core count into power profiles would make sense for Drake because:
I'd gear more into frame extrapolation since the paragraph right after the one you cited says:I read the blog post again, and I’m waffling a bit on what I’ve said before on DLSS 3. To me, there are two sections in the blog post that don’t fit together.
First:
This sounds like extrapolation to me. You render the current frame N using the super resolution network, calculate the optical flow field between frame N and N-2, and pass that to the neural network, which internally predicts how that flow field will evolve in the next frame.
It could also be frame N and frame N-1, but I am assuming that we only use non-generated frames for optical flow.
I also assume that we are only calculating one optical flow field. You could calculate several fields pairwise, which gives you a notion of acceleration like I was describing a couple of posts ago, but on closer inspection, the blog post seems pretty specific about using “an optical flow field” in the singular.
Second:
This paragraph sounds like interpolation. In that loop, you would render frame N+2 using super resolution, calculate the optical flow field between frame N and N+2, and pass that to the neural network.
The disadvantage of this method is that you are rendering the frames in advance, but the tradeoff is that you no longer need to have any notion of acceleration, since you have the exact translations at each point in the optical flow field. One optical flow field is sufficient, which fits the singular description. The neural network would only have to estimate what fraction of that translation occurs between frame N and N+1 versus between N+1 and N+2.
At this point, idk. This all hinges on how Nvidia is defining the “current frame;” if all they mean is “the frame being rendered,” then the distinction is a moot point, and it’s frame interpolation. I’m sure there will be clarification when the press embargo lifts.
I'd assume that both the game motion vectors and optical flow fields took values based on the most recently rendered frame(s) within the game itself, i.e before DLSS upscale. Therefore it would be most efficient if the same set of motion vectors from previous frames can be used for both DLSS upscaling and OFA.For each pixel, the DLSS Frame Generation AI network decides how to use information from the game motion vectors, the optical flow field, and the sequential game frames to create intermediate frames. By using both engine motion vectors and optical flow to track motion, the DLSS Frame Generation network is able to accurately reconstruct both geometry and effects, as seen in the picture below.
Funny you say that, because N64 and Drake both will have hardware based Anti-Aliasing.Hopefully the Switch 2 dock has an expansion port so a 4MB expansion pack can be inserted for improved resolutions.


Yep, exactly, there is no indication of any changes to the GPU core count in NVN2 as it is or indication of the usage of stuff related to that tech outside of one mention of a feature tangential to it iirc but there was only the one and it in itself means nothing in regards to actually being able to do that.If a 6SM configuration was always needed for handheld mode, wouldn't that be in the API as often as 12SM is? Yet as I understand it the API only ever sees 12SMs, there is no indication that it can utilize any other GPU configuration.
I mean, it's always possible that the portion of the API that leaked just happened to not have any mentions of a different core configuration for portable mode, but like I said if this theoretical 6 or 8SM mode was always used in handheld mode, then you'd expect it to show up as often as the docked 12SM configuration, right?Yep, exactly, there is no indication of any changes to the GPU core count in NVN2 as it is or indication of the usage of stuff related to that tech outside of one mention of a feature tangential to it iirc but there was only the one and it in itself means nothing in regards to actually being able to do that.
NVN2 only sees 12SMs
We should expect 12SMs in both modes.
8nm based on Thak's numbers is not viable for 12SMs in portable mode
If Tangmaster's numbers are right, then it is viable in portable mode, albeit more at OG Switch battery life even with 12SMs.
end of the story on that
Yes, it's extremely unlikely it wouldn't show up in the GPU Definition section in NVN2I mean, it's always possible that the portion of the API that leaked just happened to not have any mentions of a different core configuration for portable mode, but like I said if this theoretical 6 or 8SM mode was always used in handheld mode, then you'd expect it to show up as often as the docked 12SM configuration, right?
So while it's theoretically possible perhaps that we just simply didn't get that bit, that would be exceedingly unlikely no?